
Code review best practices in 2026 focus on keeping Pull Requests (PRs) small, automating style enforcement, reviewing for architectural intent, and holding teams to explicit review SLAs. AI coding tools now generate more code in a day than developers used to write in a week, and code review has had to adapt to that speed. These seven practices help teams review code quickly while still catching issues before they reach production.
For a broader view of how AI is changing this workflow, see the complete guide to AI code review. This article focuses on the practices that help teams maintain fast and high-quality code reviews.
1/ Keep PRs small and single-purpose
A 1,200-line PR across 40 files puts the reviewer at a disadvantage. Most reviewers read carefully for the first 200 lines, start skimming around line 400, and by line 800, they are approving on faith. Research on defect detection rates confirms this pattern: reviewer accuracy drops sharply once a diff exceeds 200 to 400 lines of changed code. The critical bugs hiding deep within a massive PR are the ones most likely to reach production.
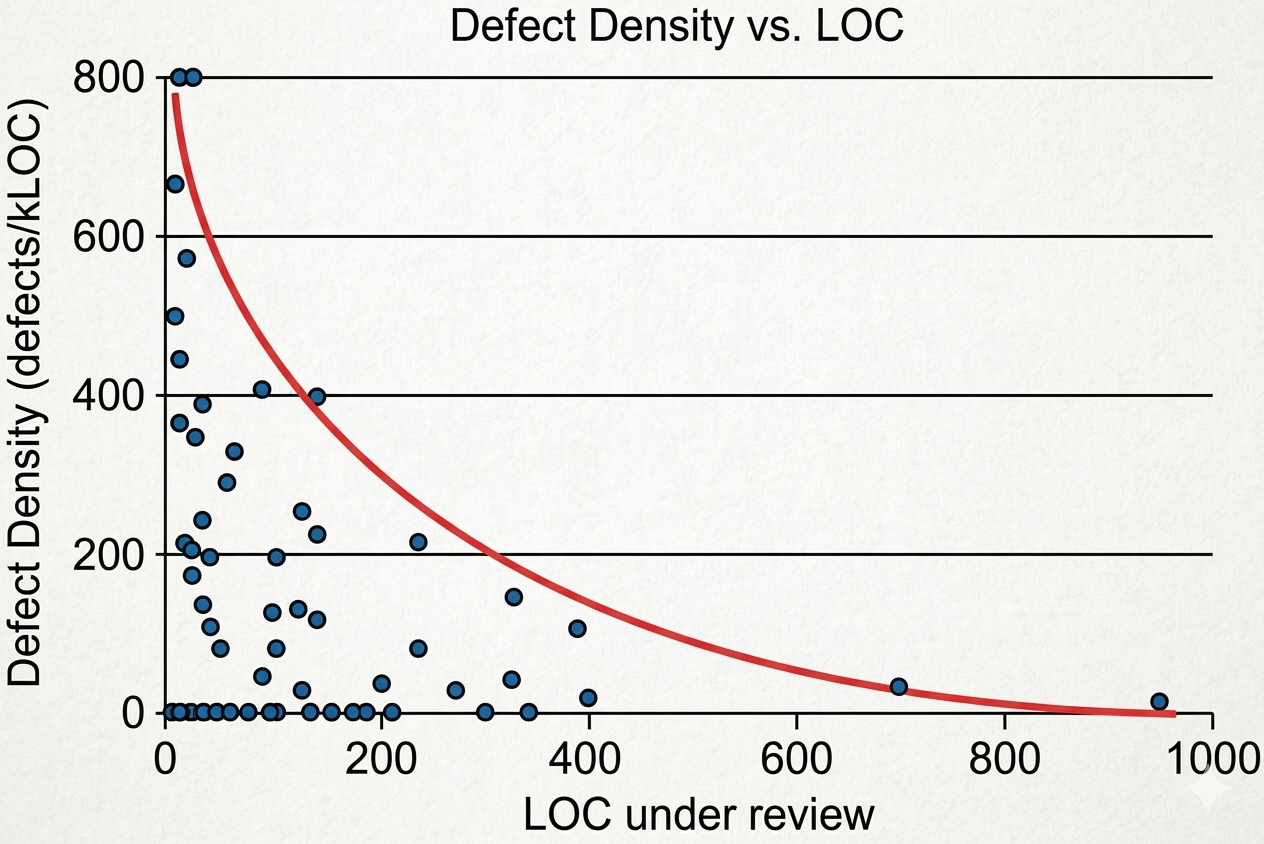
Each PR should address a single logical change, such as a feature, bug fix, or targeted refactor. If a feature spans the database schema, API layer, and frontend, split it into separate PRs so each one stays focused and can be reviewed in 10 to 15 minutes with a clear description.
Splitting PRs also surfaces design problems early. If a change cannot be explained on its own, it is likely dependent on parts of the code that it should not be tied to. That entanglement is easier to spot at the PR boundary and cheaper to fix there than in a production incident three weeks later.
2/ Write PR descriptions that save reviewers’ time
Open any busy repository, and you will find PRs with descriptions like “Updates the payments module.” That description forces the reviewer to reverse-engineer intent from a raw diff, which is slow, error-prone, and frustrating for everyone involved.
A useful PR description answers four questions:
- What changed? Summarize the code changes clearly.
- Why? Explain the problem or goal behind the change.
- What should the reviewer focus on? Highlight tricky logic, trade-offs, and risky areas.
- What is out of scope? Call out deferred work, known technical debt, and follow-up tickets to avoid unnecessary comments.
| Weak description | Strong description |
|---|---|
| “Fixed payment bug” | “Fixed timeout on Stripe webhook retry. Raised API timeout from 5s to 10s, added retry with exponential backoff, added idempotency guard. Out of scope: retry queue refactor (JIRA-1234).” |
Teams that embed these four prompts into their PR template see review cycles shorten within weeks. Reviewers ask fewer clarifying questions, and authors spend less time defending decisions they have already made intentionally.
For a structured framework to build on top of this, the code review checklist for 2026 covers what to check on every PR.
3/ Automate style checks in Continuous Integration (CI)
Debates like tabs versus spaces, trailing commas, and import ordering may be entertaining on Twitter, but they add no value during a PR review. When reviewers spend time commenting on formatting, they lose time evaluating race conditions or missing null checks.
Run linters and formatters in CI as a gate before any PR reaches a human. Tools like Prettier, ESLint, Black, and gofmt vary by stack, but the principle stays the same. When you can define a style rule clearly, enforce it automatically so that it never comes up in a review.
AI code review tools extend this further. Refacto runs on every PR and handles style checks, anti-pattern detection, and security scanning in one pass. By the time a reviewer opens the diff, it has already removed surface-level noise. The remaining questions need human attention: whether the approach fits the architecture, whether the trade-offs are acceptable, and whether the error handling will work under real traffic.
Refacto automatically catches style violations, security flaws, and anti-patterns on every PR.
Try it on your next PR for free →
4/ Review for architectural intent
Consider a function that calculates a 15% discount and applies it to the order subtotal. The code compiles, the tests pass, and the math is correct. There is just one problem: the discount should have been applied to the line item total, which excludes shipping and tax. The function works as implemented, but does not solve the intended problem. The most valuable code reviews catch this category of mistake.
Experienced reviewers read the PR description first, build a mental model of what the change should accomplish, and then check the diff against that model. When the implementation diverges from the stated intent, that gap is either a bug or a missing piece of the description.
Four questions drive this kind of review:
- Input assumptions: Where does the data come from, and does the code handle the realistic range of inputs? A function that works for positive integers but silently breaks on null or negative values is a production incident waiting to happen.
- Failure behaviour: What happens when the happy path fails? Reviewers often catch silent error swallowing, and automated tools find it harder to evaluate.
- Architectural fit: Does the change follow the patterns that were already established in the codebase? A new pattern in one service increases maintenance overhead for the team, especially when the rationale is not documented.
- Untested edge cases: Automated tests verify expected behaviour. Reviewers can identify scenarios that the author did not include in tests.
This kind of judgment requires context that lives in the team’s collective knowledge: a particular microservice already running at 80% memory, a dependency scheduled for deprecation next quarter, the business rules behind a pricing engine. AI tools handle the mechanical checks across the diff. The architectural calls depend on the humans who understand the system.
5/ Label, specify, and suggest: how to write review feedback
A review comment that says “This doesn’t look right” gives the author nothing to work with. A comment that says “Why would you do it this way?” creates defensiveness that outlasts the PR itself.
One habit improves feedback quality: mark each comment as blocking or non-blocking. A blocking comment means that the PR cannot be merged until the issue is addressed. A non-blocking comment, typically prefixed with “Nit:”, is a suggestion that the author can take or leave. When both parties know which category a comment falls into, the back-and-forth over optional preferences disappears.
The second habit is specificity. Compare these two versions of the same feedback:
| Vague | Specific and actionable |
|---|---|
| “This error handling needs work.” | “This catch block swallows the exception silently. If Stripe returns a 500, the caller will never know the payment failed. Re-throw or return an error result.” |
| “Can you clean this up?” | “Nit: this function is 80 lines. Extracting the validation logic would make both halves independently testable.” |
The best review comments describe the problem, explain why it matters, and suggest a direction. They read like a colleague thinking through a design decision out loud. That tone is achievable with practice, and it makes a measurable difference in how quickly feedback gets incorporated.
6/ Set a 24-hour review SLA
Every PR waiting in the queue is work that is done but not shipped. As time passes, the author loses context, merge conflicts build up, and the team continues work on assumptions that are not yet validated.
Review delays add up quickly, and teams often underestimate the impact on throughput. Set a simple starting point: respond to every PR within one business day. This does not require a full review. An initial pass with questions or early feedback is enough to keep progress moving and the author unblocked.
To keep the process measurable, track two metrics:
- Time to first review: how long a PR waits before someone looks at it
- Time to merge: total time from PR creation to merge
Track these at the team level using p50 and p90. This shows whether delays are consistent or tied to specific reviewers, repos, or large PRs. As a baseline, aim for:
- p50 time to first review under 24 hours
- p90 under 48 hours
Make this data visible every week through a standup, Slack update, or dashboard. Visibility helps teams stay within these targets without constant follow-up.
7/ Use AI code review as an automated first pass
AI coding tools have increased how quickly teams generate PRs, but review capacity has not grown at the same pace. More PRs arrive while the same reviewers try to keep up, leading to rushed approvals or growing backlogs.
AI code review tools address this by acting as a first pass on every PR. Refacto automatically identifies issues such as security vulnerabilities, hardcoded secrets, performance problems, and common anti-patterns, and generates a PR summary before a reviewer opens the diff.
This shifts how reviews happen in practice:
- Mechanical checks run upfront
- Reviewers begin with context instead of raw diffs
- Review time goes into design, logic, and trade-offs
AI works well at detecting known patterns across code and uses complete codebase context to improve accuracy. With JIRA integration, Refacto also checks whether the implementation aligns with the stated business requirements. It can identify missing error handling and authentication gaps, while reviewers evaluate whether the approach fits the system design and holds up across real use cases.
Teams use AI review as a reliable gate for consistent checks across every PR.
Conclusion
Code review works best when teams keep PRs small, write clear descriptions, automate repetitive checks, and respond within a defined SLA. These practices reduce friction in the review process, improve feedback quality, and help catch issues before they reach production.
AI code review fits naturally into this workflow. It runs on every PR, handles the mechanical checks, and gives reviewers a clear starting point. This allows engineers to focus on logic, design decisions, and edge cases that require real context.
Start by applying a few of these practices consistently across your team. As they become part of your workflow, reviews become faster, more reliable, and easier to scale.
